Volunteer Computing in Big Data
Volunteer computing, also called VC which can be defined as the method of obtaining higher throughput during computation using simple digital devices like smartphones, computers, laptops, and tablets. You can install a program that is capable of downloading and executing tasks from the operating servers to take part in volunteer computing.
Volunteer computing in big data is becoming one of the important fields of research these days. In this regard, we have provided a detailed overview of volunteer computing and the Big Data analytics aspects of it in this article. Let us first start by defining volunteer computing
What is volunteer computing give an example of such computing?
- Volunteer computing refers to the use of idle or less used consumer digital devices primarily to cut the cost of high-performance computation and maintenance
- The devices include desktops, laptops, and fog devices
With world-class certified engineers volunteer computing in big data is providing advanced research guidance and technical assistance to research scholars and students from top universities of the world. We have got more than twenty years of research experience in the field. Let us now have an overview of volunteer computing below
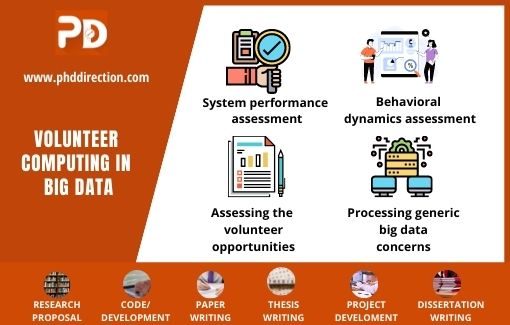
Overview of volunteer computing in big data
The following are the two important purposes for which volunteer computing is being investigated,
- Performance of volunteer computing with multiple volunteers
- Convergence of the overall performance as a function of the number of volunteers
It is important to give priority to reducing the overused or extra volunteer devices that are present to divert them to other purposes. The major aim of volunteer computing research in big data lies in the optimization of available volunteers that is utilizing a minimum number of volunteers to establish high throughput. For this purpose assimilation platform with the following characteristics are required
- System performance assessment
- Behavioural dynamics assessment
- Assessing the volunteer opportunities
- Processing the generic big data concerns
Usually, researchers reach out to us for the technicalities associated with these aspects. We also ensure our full support in the writing aspects like research proposal writing, paper publication, survey paper writing, and thesis. Let us now see about some major volunteer computing-based technologies
Key enabling technologies of volunteer computing in big data
- Edge computing
- It focuses on device-based direct data processing
- It makes use of attached sensors and gateway devices at sensor proximity
- Mist computing
- It is used in processing the extreme network data
- It consists of sensors and multiple microcontrollers
- Fog computing
- It is a network framework that ranges between data creation and storage locations
- The location for storage can be both cloud and local data center
- Centralised computing
- Mainframe computers give significance in this type
- Dumb terminals and time-sharing on the different aspects of centralized computing
- Utility computing
- It works under metered bandwidth and has self-service provisioning
- It provides for quick scalability
- Cloud computing
- Cloud Computing provides for the three different types of services As given below
- Software as a service
- Platform as a service
- Infrastructure as a service
- Grid computing
- The processing is decentralized and highly parallel
- Commoditized hardware is its specialty
For detailed explanations on all the above technologies, you can visit our website or contact us. By having a good interaction with our technical team you can get all your doubts and queries solved instantly. We will now discuss the taxonomic approach of volunteer computing in Big Data
Taxonomy of volunteer computing in big data
- Storage and data collection
- Collection of data happens through to internet of things and sensor devices
- Indexing, replication, and clustering are the processes involved in data storage
- Data processing and Data analytics
- Orchestration and abstraction layers along with IoT verticals are the components of data processing
- BDA, DA, and RTA are used in Data analytics
- Fog node connectivity
- Physical and network connections are a part of fog node connectivity
- Master-Slave, P2P, and Clusters are involved in fog node collaboration
- Distribution of data
- Data distribution is one of the key aspects of volunteer computing in big data
- QoS and QoE metrics
- The following are the important parameters used as a quality of service and experience metrics
- Cost and time
- Data and context
- Latency
- Security and privacy
- Ensuring security and privacy of personal information and the data collected has to be given more importance
Here are our developers to provide you with an appropriate explanation of all the algorithms, codes, and programs associated with every process and aspect stated above. You can get code implementation support and real-time execution help from us. Let us now look into the important criteria to make the best volunteer computing system.
What are the criteria for good volunteer computing?
- It should be an easy to use platform for both programmers and volunteers providing for better opportunities to develop new applications and encourage many volunteers respectively
- It has to be capable of being applied to diverse applications apart from mathematics and scientifically significant problems
- It must be extended into complicated patterns of communication and the coarse-grain applications while it should not be limited to parallel and master worker style of applications
- It must ensure reliability even when malicious volunteers are present without compromising on network performance
We help you in meeting all the demands of the best volunteer computing system. Authentic research materials and expert advice are the essential combinations to carry out the best research work. We ensure to provide all these facilities readily to you. Let us now see the issues and concerns associated with volunteer computing in big data below
Two major issues of volunteer computing in big data
- Specialised air conditioning systems are required in place of data centers for the removal of hardware heat whereas such systems or not required by the consumer devices
- Ambient heating is contributed by consumer devices in cold climates which lead to the net-zero cost of computing. Therefore global deployment of volunteer computing is looked upon for its efficiency over data center computing
For many years our research experts have been working in close contact with the top researchers of the world to find solutions to these problems. That we are aware of the recent trends and developments in volatile computing research. Let us now see how monitor computing is prepared for high throughput applications
What are the reasons to prefer volunteer computing?
- Since the most important reason for using volunteer computing is to increase the task completion rate it is highly suited for high throughput computing
- Also reducing the turnaround time for completing a task is not the primary goal of volunteer computing
- In cases of huge memory workloads, large storage demands and the higher ratio between network communication and computing, volunteer computing in Big Data cannot be used
Hence without a doubt volunteer computing is highly accepted and suited for high throughput computing applications.
We have committed and dedicated teams of experienced and qualified developers, subject matter experts, engineers, and writers to support you in all aspects of your research. We provide you with customized and holistic research guidance. Let us now discuss the unique characteristics of volunteer computing
Unique features of volunteer computing
- External devices with different hardware and software properties can be deployed in a volunteer computing network
- Since the host is not available all the time uncertainty in task turnaround time prevails
- Volunteer computing is very large and can be scaled up to millions of tasks and computers in a day. The resources have to be voluntarily recruited and retained for creating the resource pool
- Easy to install and run software are preferred by clients in case of VC
For these reasons, volunteer computing is being adopted by many areas of day-to-day applications. Our technical team is always ready with the essential support and guidance needed to make your research experience highly interesting. We also help in solving the research problems in volunteer computing. In this respect let us now discuss the volunteer computing research issues
Research issues in volunteer computing
- Data Center level
- Security in distributing the content and computation of data
- Challenges in distributed and verifiable computations
- Identifying, aggregating, and integrating data and big data analytics
- Device level
- Preserving confidentiality
- Authentication
- Privacy
- Identity and data
- Usage and location
- Lightweight trust management
- Service, network, and core level
- Detecting rogue fog nodes and intrusions
- Verifying identity and trust management
- Access control and lightweight protocol design
- Privacy conserving packet forwarding
Our researchers have dealt with all these issues and have devised potential solutions to many of them. We are here to supply you with properly refined and religiously collected research data from top research journals, standard references, and benchmarks sources so that you can keep yourselves updated and informed of all the recent breakthroughs in the field. Let us now see the recent research topics in volunteer computing.
Research Topics of Volunteer Computing
The following are the most popular research topics in VC. On all of these subjects, we provide ultimate research assistance.
- Load balancing
- Task scheduling
- Provisioning of resources
- Quality of service enhancement
Our major goal is to inspire scholars to come up with their ideas for research projects. To accomplish so, they must make some well-informed decisions. As a result, we are taking efforts to provide you with the latest volunteer computing in big data project ideas that we have directed as well as those that are currently trending. Get in touch with us to know more details. Let us now see the research directions of volunteer computing
What are the research directions of volunteer computing?
- Customisation for users and establishing embedded features
- Enhancing the service performance and resource profiling
- Real-time application starring
- By utilizing internet of things applications the following adder growths can be envisioned
- Vertical management and the service coordination
- Customisation of resources and creating dynamic cloud
- Time-sensitive operations and micro clouds based on VM
We provide detailed practical explanations with massive resources that are both authentic and reliable to carry out your research effectively. The technologically updated technical team with us has the highest potential to solve any kind of research issues with volunteer computing. We also provide proper descriptions and notes on the techniques, tools, and coding needed for your project. Let us now see the big data tools that are used for volunteer computing
Big data Tools used for volunteer computing
- Spark – supportive too in-memory calculations
- Cassandra – availability, and scalability are maximum
- Hadoop – Big Data storage, processing, and analysis
- Mongo DB – useful in performing cross-platform capacities
- Storm – processing and bounded data streams
Without resource overuse and with minimal volunteers achieving high optimization and overall performance is the target of volunteer computing. In case you are working with a suitable platform then the next need is a big data algorithm. MapReduce is one of the best and successful big data and got them that been used in various applications. You can get complete guidance concerning all deep learning algorithms and especially MapReduce from our experts at all times. Let us now look into the prominent volunteer computing based big data techniques below

Big data techniques for volunteer computing
The following are the crucial big data methodologies for volunteer computing networks
- Loop control
- Loop aware task scheduling is used for scheduling the tasks
- It provides for checkpoints in fault tolerance
- It is used in Big data analysis applications involving multiple iterations
- K means clustering
- Cache aware decentralized task scheduling process is used
- It provides for decentralized control Framework in fault tolerance
- Scientific Discovery and data-intensive computing are the benefits of this mechanism
- Additional combine phase apart from reducing phase
- MapReduce based statics scheduling is used
- Checkpointing fault tolerance is followed in this mechanism
- MapReduce computations with multiple lighter actions are its major benefit
- Updates and detects
- MapReduce static scheduling mechanism is used
- Fault tolerance checkpointing is utilized
- Performance increase in the manifold where there is no benefit using task-level memorization
- Iterative computation with distinct map and reducing functions
- Statics scheduling is used for MapReduce
- It provides for checkpointing in fault tolerance
- It enables asynchronous map task execution and reduces the overhead by eliminating static shuffling
So far we have seen the importance of volunteer computing in establishing a cost-effective and environment-friendly alternative computer framework in place of the expensive and centralized infrastructure.
You can use volunteer computing for tasks that involve large utilization of resources like Big Data analytics and scientific simulations by aggregating idle computer devices like desktops, routers smart.
For harnessing the complete power of volunteer computing novel techniques, procedures, algorithms, and standards have to be devised. Our experts are also working to improve the existing technologies to enhance volunteer computing in big data. Check out our website for the successful projects that are both completed and ongoing in our organization.
Why Work With Us ?
Member Book
Publisher Research Ethics Business Ethics Valid
References Explanations Paper Publication
9 Big Reasons to Select Us
Senior Research Member
Our Editor-in-Chief has Website Ownership who control and deliver all aspects of PhD Direction to scholars and students and also keep the look to fully manage all our clients.
Research Experience
Our world-class certified experts have 18+years of experience in Research & Development programs (Industrial Research) who absolutely immersed as many scholars as possible in developing strong PhD research projects.
Journal Member
We associated with 200+reputed SCI and SCOPUS indexed journals (SJR ranking) for getting research work to be published in standard journals (Your first-choice journal).
Book Publisher
PhDdirection.com is world’s largest book publishing platform that predominantly work subject-wise categories for scholars/students to assist their books writing and takes out into the University Library.
Research Ethics
Our researchers provide required research ethics such as Confidentiality & Privacy, Novelty (valuable research), Plagiarism-Free, and Timely Delivery. Our customers have freedom to examine their current specific research activities.
Business Ethics
Our organization take into consideration of customer satisfaction, online, offline support and professional works deliver since these are the actual inspiring business factors.
Valid References
Solid works delivering by young qualified global research team. "References" is the key to evaluating works easier because we carefully assess scholars findings.
Explanations
Detailed Videos, Readme files, Screenshots are provided for all research projects. We provide Teamviewer support and other online channels for project explanation.
Paper Publication
Worthy journal publication is our main thing like IEEE, ACM, Springer, IET, Elsevier, etc. We substantially reduces scholars burden in publication side. We carry scholars from initial submission to final acceptance.